Stop right-click saving: How to automatically scrape every image from a website
How you can use Gaffa to read a site's sitemap to get all urls and scrape images from all pages
Jan 21, 2026
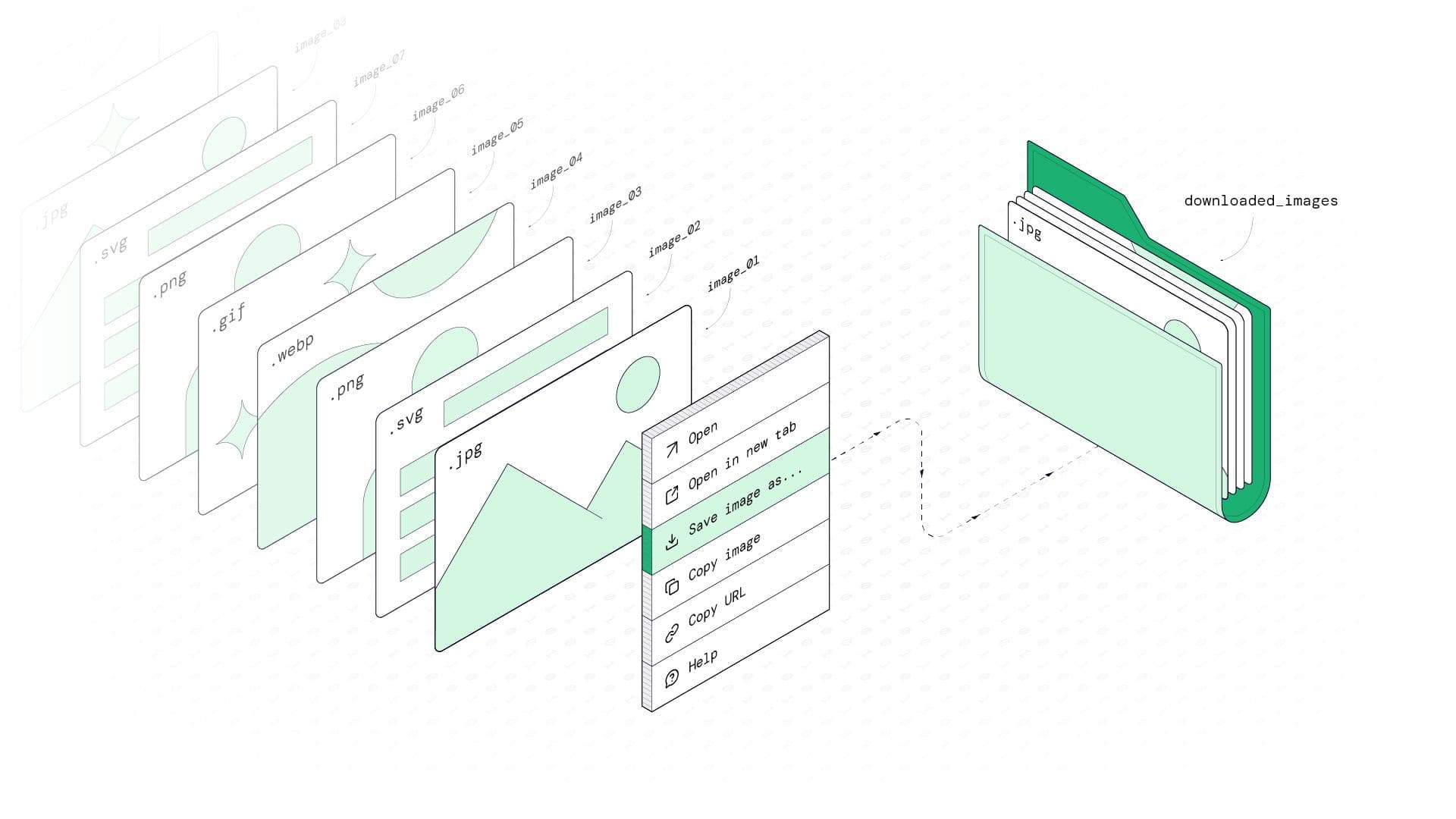
Manually saving images from the web is a tedious, time-consuming chore. This tutorial shows you how to automate it at scale using Gaffa's Mapping and Browser Requests endpoints. We'll use Python to find every page on a site, scrape every image from each page (including JavaScript-loaded ones), and download them all automatically.
Consider these scenarios: A marketing team needs to analyze the visual branding of five different competitors. Or perhaps there's a researcher building a dataset of thousands of product images to train a machine learning model. Then there's the design agency migrating a client's old website who needs to securely archive all their original assets.
What do they all have in common? Someone, at some point, is facing the task of manually right-clicking and saving hundreds, maybe thousands, of images. It's error-prone, incredibly boring, and frankly, a waste of valuable time.
At Gaffa, we recently helped a communications company do exactly this, saving them days of manual work. In the process, we used two powerful features of our API: the Site Mapping endpoint and the enhanced download-file browser request action.
In this post, we'll show you how we did it. You'll learn how to build a Python script that automatically hunts down and downloads every image from any website, no manual effort required.
Why You Can’t Just "View Source" Anymore
If you've ever tried to scrape a modern website with a simple script, you've likely run into a wall. Why is it so hard?
- JavaScript: A huge portion of the web is built with frameworks like React, Vue, and Angular. The HTML you get from a simple requests.get() call is often just a shell. The actual content, including images, is loaded asynchronously by JavaScript after the page renders.
- Lazy-Loading: To improve performance, sites commonly use lazy-loading. Images only appear in the HTML (data-src attribute) and load into the src attribute as you scroll down the page.
- Blocks & Rate-Limiting: Making too many requests from a single IP address will quickly get you blocked.
This is where a tool with a real browser engine becomes essential. It renders the page fully, executing all the JavaScript, just like a human user would see it. That's the power we'll leverage with Gaffa.
The Plan: How We'll Scrape All Images
Our strategy is straightforward:
- Map the Territory: First, we use Gaffa's site/map endpoint to find every single page on the target website. It intelligently parses sitemaps and site structure to give us a list of URLs to process.
- Render Each Page: For each URL, we launch a headless browser in the cloud. We tell it to wait for all images to load and then hand us the fully-rendered HTML (the Document Object Model, or DOM).
- Find & Download: We parse that final DOM to find every <img> tag, extract their source URLs, and download the files using Gaffa's download_file action. This ensures each request uses a real browser fingerprint and residential proxy, making your scraping activity appear as legitimate user traffic while leveraging Gaffa's caching system to reduce server load.
The Code: Automated Image Scraping in Python
Let's break down the key parts of the script. You can find the complete, ready-to-run code in our GitHub repository.
Step 1: Fetch Every URL on the Site
The site/map endpoint is our starting point. It does the heavy lifting of discovery by reading the sitemap, traversing possible link-outs and retrieving every page available on the website you want to scrape.
Get Sitemap
Step 2: Capturing the Real Page (after JavaScript)
This is where the real magic happens. We use a browser request with the capture_dom action to get the real HTML. The Gaffa API makes sure that the website is rendered first which is often one of the main issues when using traditional web scraping frameworks.
Capture DOM with Gaffa
Step 3: Finding and Saving the Images
With the real HTML in hand, we extract image URLs using a simple regex pattern and use Gaffa's download_file action for reliable downloads. This also allows us to use caching, which avoids downloading the same image over and over again and putting load onto the target server.
Download files using Gaffa
Why Use Gaffa for Downloading?
The download_file action provides three crucial advantages over standard download methods:
- Stealth & Success Rates: By using rotating residential proxies and real browser fingerprints, your requests appear as legitimate user traffic, dramatically reducing the chance of being blocked.
- Responsible Caching: With max_cache_age set to 24 hours, repeated requests for the same image are served from cache, sparing the target website's servers from unnecessary load.
- Built-in Reliability: Gaffa's infrastructure automatically manages request pacing and retries, but remember to always respect reasonable rate limits and check robots.txt before scraping.
- Automatic Format Detection: Gaffa's API provides the correct file extension directly in the download URL, eliminating the need for complex content-type parsing and making the download process more reliable.
When you run the script, you'll see a satisfying log of progress as it systematically works through the site:
- Retrieving sitemap URLs.
- Capturing DOM URL.
- Retrieving DOM.
- Retrieving download URL.
- Downloading image.
So, What Can You Actually Build With This?
The use cases go far beyond simple image collection. This kind of automation is a superpower for:
- Competitive Intelligence & Market Research: Analyze product photography styles, branding consistency, and advertising campaigns across entire industries.
- AI and Machine Learning: Build large-scale, curated image datasets for training computer vision models on anything from fashion to real estate.
- Competitor Tracking & Trend Analysis: Create a timeline of how competitors' websites and visual content evolve by running automated scans weekly or monthly. Track branding changes, product launches, and marketing campaigns over time to stay ahead of market trends.
- UX & Design Inspiration: Create massive mood boards or collect UI patterns from across the web to inspire your next project.
- Performance Auditing: Scan your own site to find unoptimized images that are slowing down your page load times.
Scrape Responsibly, Build Amazing Things
It's important to use this power wisely. Gaffa’s built-in caching helps prevent overloading servers, but it's on all of us to be good citizens of the web and always check a website's robots.txt file and terms of service before scraping.
The beauty of this approach is that it abstracts away the immense complexity of running browsers at scale. You don't need to manage proxies, worry about getting blocked, or scale up a server farm. You just write a few lines of code that describe what you want, and Gaffa handles the rest.
Ready to stop right-clicking and start building? Sign up to Gaffa and start building
You can find a more detailed tutorial in our docs.
Frequently Asked Questions
Why can't I just use a simple Python script to scrape images from modern websites?
Most modern sites use JavaScript frameworks and lazy-loading, meaning images aren't in the initial HTML. A simple requests.get() call returns a shell page without the actual content; you need a real browser engine to render it fully.
How does Gaffa find every page on a website to scrape?
Gaffa's site/map endpoint reads the site's sitemap and traverses its link structure to return every available URL, saving you the manual work of discovering pages before scraping them.
What is the download_file action, and why use it over a standard download?
It downloads files using rotating residential proxies and real browser fingerprints, making requests appear as legitimate user traffic. It also handles caching, automatic file extension detection, and request retries, things you'd otherwise have to build yourself.
How does Gaffa handle lazy-loaded images that only appear on scroll?
The wait action tells Gaffa to pause until image elements appear in the DOM before capturing them, ensuring lazy-loaded images are included in the final HTML you parse.
Will scraping images at scale get my IP blocked?
Not with Gaffa. It uses rotating residential proxies and real browser fingerprints, so requests appear as normal user traffic rather than automated scraping.
Is there anything I should check before scraping images from a website?
Always review the site's robots.txt file and terms of service before scraping. Gaffa's built-in caching also helps reduce unnecessary load on target servers.
