Turn Web Content Into Structured Data With Gaffa’s Parse_JSON Action
See how Gaffa's Parse_JSON action uses AI to extract clean, structured JSON from any web page with no HTML parsing, no custom scripts, just the data you need.
May 17, 2026
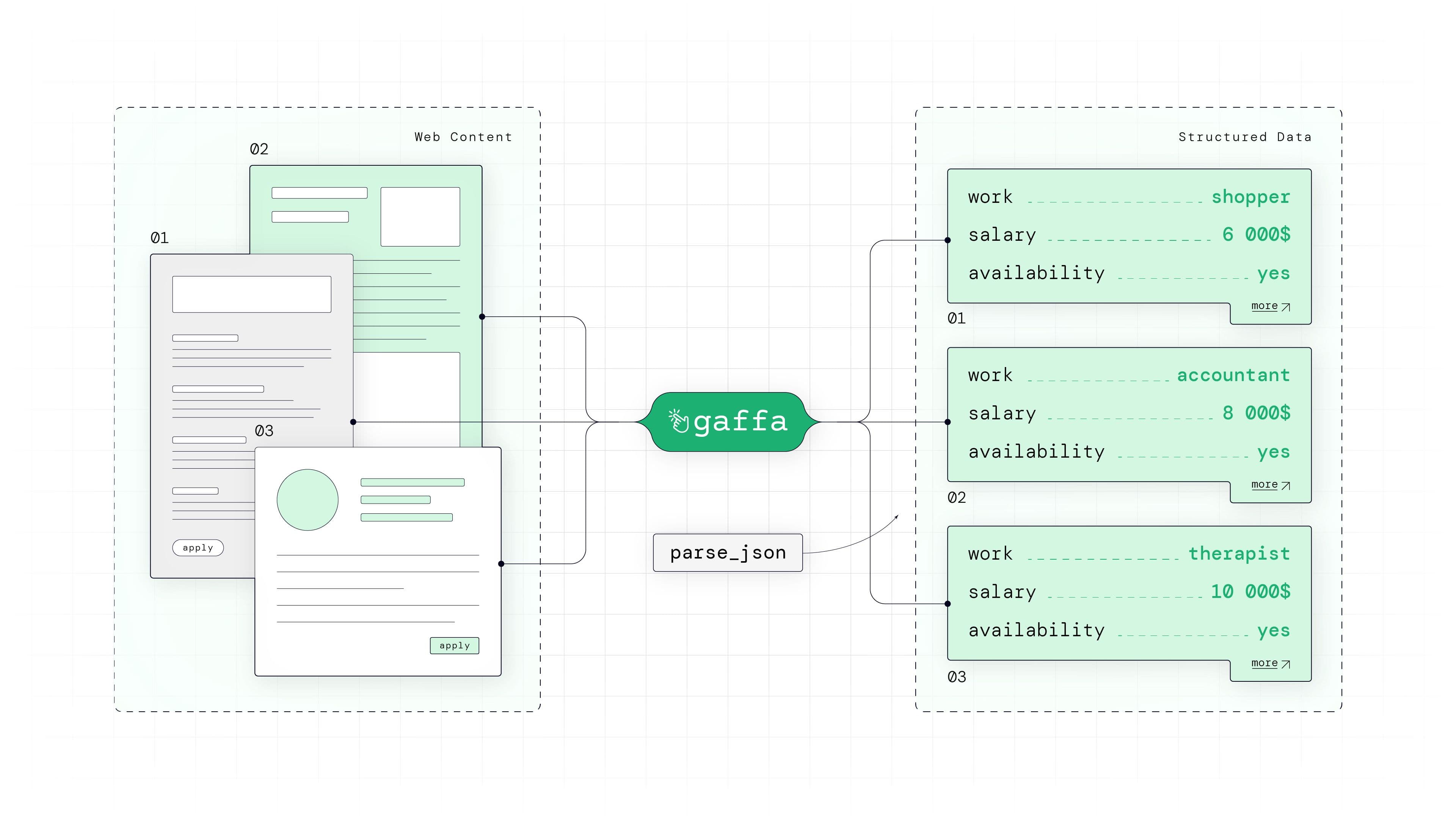
Traditional parsing libraries can only extract what's explicitly in the HTML structure. But what if you need to summarize content? Or convert unstructured text into a specific data format? That's where AI-based extraction becomes important.
Gaffa’s parse_json action uses AI to understand web content semantically rather than structurally. Instead of using selectors that break with every design change, you simply describe what data you want, and the AI extracts it, even from unstructured content.
In this post, we’ll explore what parse_json does, how it works, and why it’s a powerful building block for web automation, data extraction, and AI-driven workflows.
The challenge of extracting unstructured data from the web
Most web scrapers are built using CSS selectors, and they work perfectly until the website design changes. Then your scraper breaks, often without warning, because companies don't announce site updates to scrapers (unfortunately!).
Industry data shows that developers spend 10-20% of their scraping time just fixing broken selectors. It's a maintenance nightmare that scales poorly as you scrape more sites.
Selectors aren’t the only challenge. The data you need might not be structured in an element. Take a job posting scenario where the salary info is buried inside a paragraph. "The position offers $80-120K annually depending on experience." In such a case, extracting those specific numbers requires a complex regex pattern, which is unreliable and may break with slight changes in wording. An alternative to this is manual extraction, which is itself costly and tedious.
PDF extraction is even harder. Tables span pages. Text flows in unpredictable ways. You need specialized libraries that could still miss content or fail in unexpected ways.
parse_json takes a completely different approach. Gaffa extracts the rendered page content, sends it to a language model along with your schema definition, and the AI structures the data according to your specifications. There are no selectors to maintain if the website layout changes - if the content remains, your extraction still works.
Using parse_json
To extract structured data from a web page or PDF, you send a POST request to the /v1/browser/requests endpoint with a JSON payload containing your schema definition.
Here's the basic structure
parse_json basic example
A schema tells parse_json what data to extract and how to structure it. Every schema has three key components:
- name: A descriptive identifier for your schema
- description: Helps the AI understand what you're extracting
- fields: Array of fields defining your data structure
Here's an example using the Gaffa demo site, where Gaffa analyzes the form and tells you exactly which fields are present, their types, whether they're required, and their validation rules. This is incredibly useful for form automation workflows. For example, you could build a tool that analyzes any web form to identify all required fields, fills them, and submits the form — like this one.
Auto-filling web forms with parse_json
parse_json address form
In the examples above, we used "gpt-4o-mini", a lightweight model, and in our testing, it performs very well on structured extraction tasks such as form parsing and document analysis. The parse_json action allows you to select the model as per your use case. We’re also continuing to expand model support, so you’ll have even more options as the platform evolves.
This request returns a response containing all the requested information. No selectors. No HTML parsing. Simply describe what you want, and receive structured data in return.
output
One of the most important things to notice in the example above is that the output strictly follows the schema and instructions we provided. We didn’t tell Gaffa where elements lived in the DOM, nor did we hardcode selectors. All we did was define the fields we wanted, and the response followed those instructions. This schema-driven approach makes extraction easy. As long as the page still contains the information, your extraction holds up even when the site is redesigned.
What you can extract
Turning web content into structured data is a foundational capability for modern automation, and with parse_json, Gaffa provides a flexible, schema-driven way to extract meaningful data from real, rendered web pages and documents without the challenges of traditional scraping. Some other common use cases include:
- E-commerce monitoring - Extract product names, prices, availability, and reviews in a consistent format,even as product pages evolve.
- Content extraction and summarization - Pull article titles, author information, and metadata, or ask the AI to generate summaries of page content in your desired format.
- Structured data from tables - Convert HTML tables into clean JSON arrays, regardless of how they're styled or nested in the page structure.
- Contact information extraction - Easily extract names, emails, phone numbers, and addresses from contact pages, even across sites with wildly different structures.
parse_json also works with PDF documents, making it easy to extract structured data from research papers, invoices, contracts, and reports without needing complex PDF parsing libraries.
Whether you’re automating form workflows, extracting data from PDFs, or building intelligent agents, parse_json helps bridge the gap between human-designed interfaces and machine-ready data.
For a real-world example of parse_json in production, see how we used it to build a personalised news plugin for TRMNL that turns any website into a feed on your e-ink display.
Why is Gaffa's JSON parsing different?
Unlike many JSON extraction tools that return loosely structured output, Gaffa allows you to rigidly define the schema and explicitly control the expected structure. The action validates the model’s output against your schema, ensuring predictable and reliable results.
Schemas can be defined inline for one-off requests, or saved to your account and reused across multiple workflows using the schema management endpoints. This makes it easy to standardize extraction logic across teams and projects.
The parse_json action is also priced to be accessible, especially when paired with lightweight models like "gpt-4o-mini," allowing you to balance cost and performance depending on your workload.
parse_json is one of Gaffa's most flexible actions, and a powerful foundation for more advanced automation workflows. To see what else is possible, browse the full list of actions in the official documentation, or head to the API Playground to try pre-built requests and tweak them to suit your needs.
Frequently Asked Questions
What is Gaffa's parse_json action?
It's an AI-powered action that extracts structured JSON data from any web page or PDF. You define a schema describing what you want, and the AI extracts it, with no HTML selectors or custom scripts needed.
How is parse_json different from traditional web scrapers?
Traditional scrapers rely on CSS selectors that break when a site's layout changes. parse_json works semantically, so as long as the content is on the page, your extraction continues to work.
Can parse_json extract data from PDFs?
Yes. It works on PDFs as well as web pages, making it easy to pull structured data from invoices, contracts, research papers, and reports without specialized parsing libraries.
What AI models does parse_json support?
You can choose your model per request. Gaffa currently supports models such as gpt-4o-mini and is expanding its support over time, so you can balance cost and performance based on your workload.
How do I define what data parse_json should extract?
You write a schema with three parts: a name, a description, and a fields array. This schema is sent with your POST request to the /v1/browser/requests endpoint, specifying exactly what the AI should return.
What are the most common use cases for parse_json?
E-commerce monitoring, article metadata extraction, HTML table conversion, contact info scraping, PDF data extraction, and automated form analysis are the most popular use cases.
