How to extract & simplify a webpage DOM with Gaffa
How you can use Gaffa's Browser Request API to extract the full DOM of a webpage and simplify it to remove unnecessary elements
Jul 18, 2025
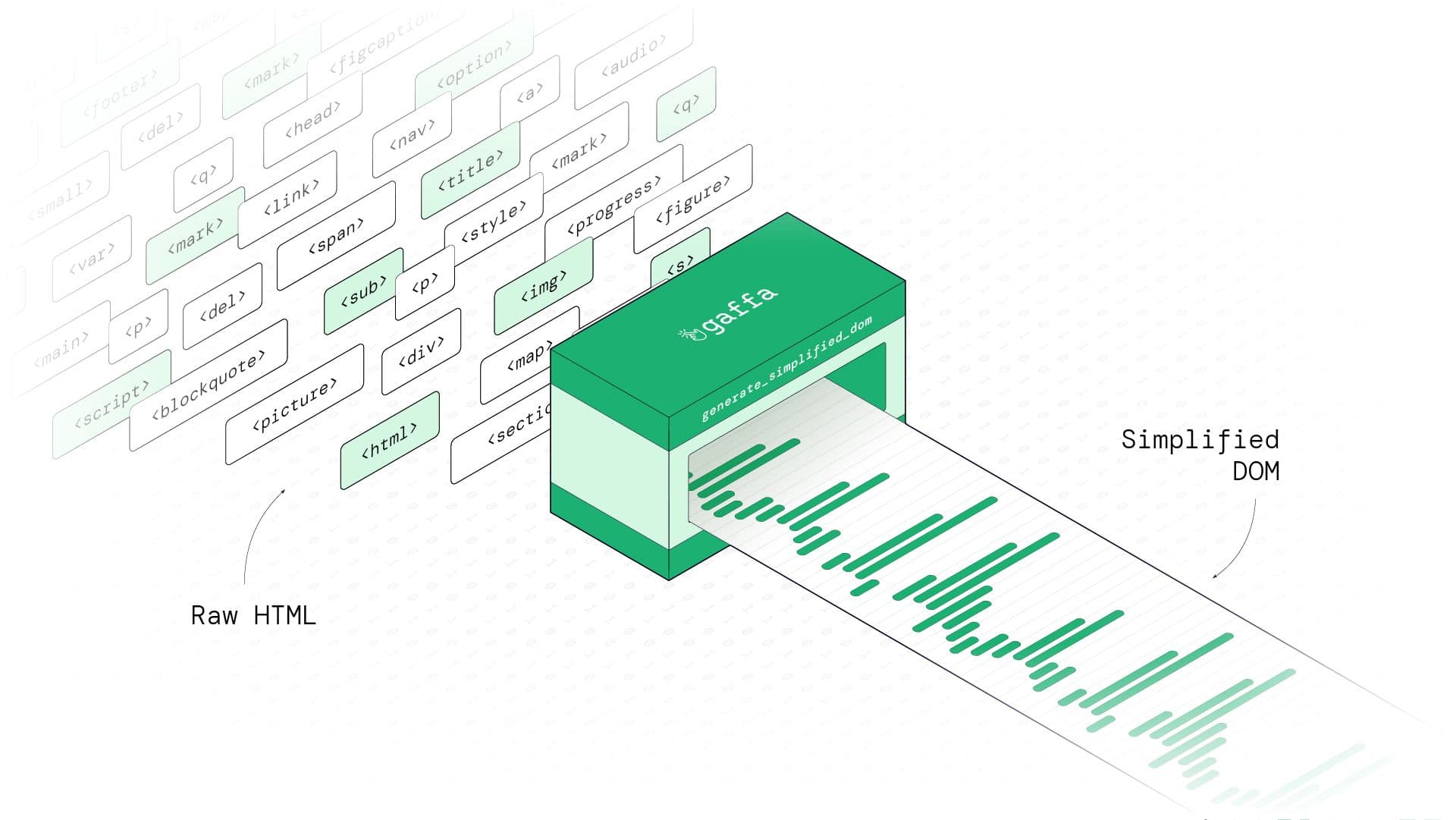
Building AI agents or AI-powered web automations, working with raw webpages can be difficult. Most HTML pages include useless elements that can become problematic when you are trying to extract meaningful data or feed clean content into an LLM. These elements include things like <style> tags, linked stylesheets, <script> blocks, tracking pixels, SVG icons, and empty or hidden nodes. These add weight to the raw DOM, increasing token usage and making LLM hallucinations more likely.
Gaffa uses a real browser to render pages by default - we call it headful as the opposite to headless which is the default with most other scraping or browser as a service products. This means the page loads exactly like it would on an actual device with JavaScript fully rendered and the DOM including all dynamic content - essential for scraping modern web apps. Gaffa’s Browser Request API has two actions that help you work with the DOM for a webpage, capture_dom and generate_simplified_dom:
- capture_dom - lets you capture the entire DOM of a webpage, including JavaScript-loaded content, which you can then process in your existing codebase or data extraction workflow.
- generate_simplified_dom - distills that raw HTML down to just the useful parts, removing unnecessary tags, styles, scripts, and other clutter, leaving you with a clean, structured DOM ready for further processing.
Simplifying the DOM is especially useful as it can reduce HTML size by 50–80% on some pages, saving thousands of tokens when feeding content into an LLM, without losing essential context. It’s equally useful as input for further processing/data extraction in your scripts, such as extracting elements with Python and beautifulsoup.
Using capture_dom to Retrieve Raw HTML
The capture_dom action lets you retrieve the complete Document Object Model (DOM) of a web page. This includes not just the static HTML served by the server, but also any Javascript-generated content.
To retrieve raw HTML with fully rendered Javascript from a web page using Gaffa, you send a POST request to the /v1/browser/requests endpoint with the following JSON payload:
To retrieve raw HTML with fully rendered Javascript from a web page using Gaffa, you send a POST request to the /v1/browser/requests endpoint with the following JSON payload:
Extracting the rendered DOM from a web page
As a sidenote, Gaffa makes it easy to rotate IPs or geolocate requests using residential proxies. Just set the proxy_location field to your desired region (like "us", "de", or "sg").
This will return a .txt file containing the raw HTML DOM of the current page at the time the request is made, with this response:
RAW DOM Response
Getting the raw means we are getting a lot of content including scripts, nav bars, stylesheets, sidebars, ads, and other elements that don’t contribute to the actual content and if sent to an LLM will lead to extra token usage and potentially harm performance.
That’s where the generate_simplified_dom action comes in...
The raw DOM after rendering the page in our headful browser
Using generate_simplified_dom to clean the DOM
Using the generate_simplified_dom action, we can clean and distill the HTML down to just the essential parts. It removes elements that typically add unnecessary noise to the HTML without containing any meaningful information for later data extraction, helping you focus on what's valuable.
The JSON payload will remain the same, the only change would be to change the action type to match the current action.
Simplify DOM Code
This will output a cleaner version of the page's DOM to a .txt file stripped of scripts, stylesheets, inline styles, and SVG paths. This reduction means fewer tokens used when feeding the data into an LLMs, ideal for summarization, Q&A, or fine-tuning tasks. It could also be useful if training a model on the HTML structure of different sites.
The simplified DOM with some elements which aren't important to the page content removed. In this example, the output was reduced by 20% but in less content-heavy sites or that use more inline styles the reduction will be much more.
Capturing and simplifying the DOM with Gaffa makes working with and extracting data from the DOM really easy. Depending on the task at hand, whether you're building scrapers or just trying out to declutter content capture_dom will give you the full HTML structure from the fully rendered version of the page in a real browser, while generate_simplified_dom will distill it into something clean, focused, and easy to work with.
These actions are some of Gaffa’s simpler features, but they also provide the foundation for more advanced workflows.
- Check out the full list of Gaffa actions in the official documentation.
- Experiment in the API playground, where you can try pre-built requests and tweak them to suit your needs.
Frequently Asked Questions
How do I capture the full rendered HTML of a page using Gaffa?
Use the capture_dom action. It returns the complete DOM including JavaScript-loaded content, exactly as it appears in a real browser, not just the initial static HTML.
How do I get a clean, stripped-down version of a page's HTML?
Use the generate_simplified_dom action. It removes scripts, stylesheets, SVGs, tracking pixels, and empty nodes, leaving only the content that matters for extraction or LLM input.
Why does raw HTML cause problems when fed into an LLM?
Raw pages contain scripts, tracking pixels, and inline styles that add no useful context. This inflates token usage and increases the likelihood of LLM hallucinations.
How much can generate_simplified_dom reduce HTML size?
It can reduce HTML size by 50–80% on some pages, saving thousands of tokens without losing the essential content needed for extraction or LLM processing.
Does Gaffa render JavaScript before capturing the DOM?
Yes. Gaffa uses a headless browser by default, meaning pages load exactly as they would on a real device, with JavaScript fully executed and dynamic content included.
Can I use the captured_dom with my own parsing tools, such as BeautifulSoup?
Yes. Both capture_dom and generate_simplified_dom return a .txt file containing the HTML, which you can fetch and process with any library in your existing workflow.
How do I route requests through a specific country with Gaffa?
Set the proxy_location field in your request payload to your desired region, such as "us", "de", or "sg", and Gaffa routes the request through a residential proxy in that location.
